Switched Node Docker image from node to node-slim, improving performance when running docker-compose up.
Switched Django docker image from python-alpine to python-slim in Postgres, improving performance when running docker-compose up. While MySQL worked better with python-alpine.
Improved internal compiler's e2e tests so generated code is more reliable in all languages and frameworks.
Updated README to explain better different alternatives to run the project and improving migrations documentation for TypeScript.
General bug fixes for linting issues in Typescript implementation.
Fixed dependencies errors in the app's RUN UNIT TESTS console for Typescript - GraphQL.
Added standardization between TypeORM and Sequelize implementations for Typescript.
Our goal at Imagine has always been to make the life of developers easier by creating a useful tool that generates well-written, clean code for the most used languages and frameworks out there. After our first release we received a lot of awesome feedback from developers all over the world, and one of the things that stood out the most was the request to add Typescript support.
Well, after a lot of work over the past month we have finally added it and it's ready for you to use in real world projects!
With our v1.1.0 release now you can generate Node code using Typescript as easy as always through our intuitive UI, just select Typescript in the frameworks section, and you'll be ready to create your project using the best practices with our cutting-edge project starter.
These are the features of our V1.1's Node generator:
A minimum of 1000 lines of clean Typescript and settings code autogenerated from your spec. The amount of generated code depends on the number of models and relations you define, but it's ensured to be a clean codebase that you can easily download, run and update.
You can select between NPM and Yarn as your package manager
Linting support using ESLint. You can select between google, airbnb and standard for your configurations.
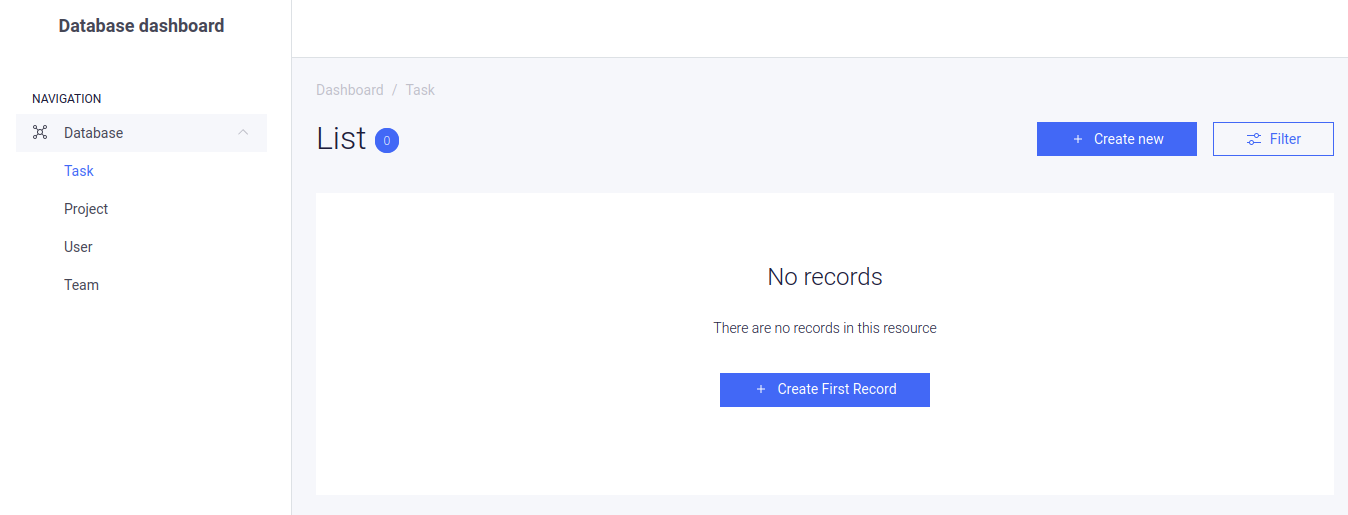
Admin Bro support for straightforward data management. You can try it directly from our UI!
Well architected project structure that makes it really easy to extend the codebase to fit all your requirements and your business logic.
We'll also add in the future much more awesome features to our platform, and have the following possibilities in our roadmap:
Backend features:
NoSQL databases (MongoDB, DynamoDB)
Support for migrations
Kubernetes deployment scripts
Logging and monitoring
Authentication (via multiple providers)
Payments integration (via multiple providers)
Frontend frameworks:
React (incl Redux, Hooks)
React native
Frontend features:
API calling
Views & components
Storybooks
We hope you find Imagine useful. Join our Slack and Discord communities to share your feedback and be the first to know about new releases and updates in our platform.
Imagine is a labor of love for our founders Anusheel Bhushan and Privahini Bradoo. They have overseen the build out of several (80+) software products over the years. And each time they were acutely reminded of how much redundancy there exists while writing code, especially for commonly used components and features in software applications.
Also, while we at Imagine believe the current version of the no-code movement is awesome, we've found it hard to scale these solutions for applications that required any reasonable level of custom logic.
So today we're happy to announce the release of Imagine V1 - a configurable, cross-framework platform for developers to easily generate high-quality code for common application components, which they can seamlessly integrate into their projects, without any lock-in - and allowing them to focus on writing custom business logic.
Our goal for this release has been from day one to make the generated code clean, readable and following known software best practices (we love the 12—factor app philosophy!) - basically indistinguishable from what a skilled engineer would write.
Our V1 release allows you to define your starter settings, data models and relations via a UI and we instantly generate code for a dockerized project starter, ORM, REST & GraphQL CRUD APIs and tests in both Django & Node.js.
These are the features of our V1's Node generator:
A minimum of 1800 lines of clean Javascript and settings code autogenerated from your spec. The amount of generated code depends on the number of models and relations you define, but it's ensured to be a clean codebase that you can easily download, run and update.
REST and Graphql APIs generation for each of your defined models using Express and Express Graphql. With out of the box request validation using express-validation.
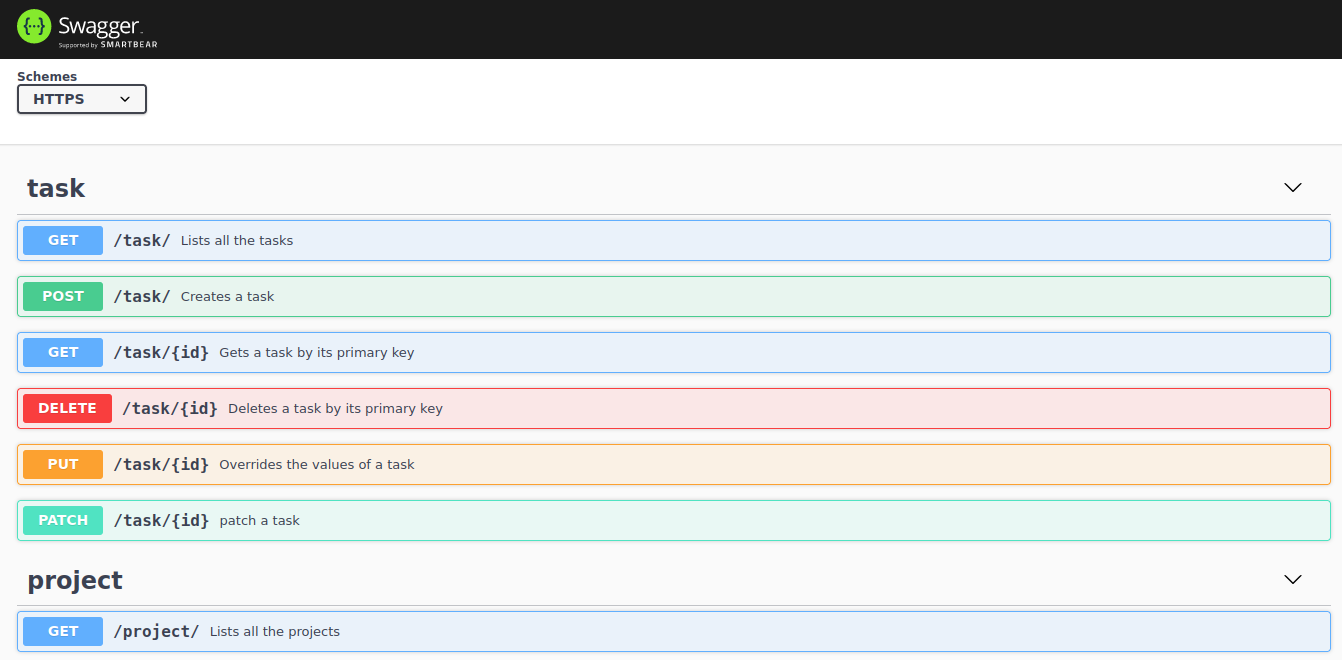
Swagger generation for the defined REST API. You can try it directly from our UI!
ORM generation using Sequelize, where you can select between SQLite, Postgres and MySQL as your database.
Safe models and relations definition using our intuitive UI.
These are the features of our V1's Django generator:
A minimum of 1500 lines of clean Python and settings code autogenerated from your spec. Similarly to our Node generator the amount of code depends on the number of models and relations you define, but it's also ensured to be a clean codebase that you can easily download, run and update.
We'll also add in the future much more awesome features to our platform, and have the following possibilities in our roadmap:
Backend frameworks:
Node/Typescript (Comming soon)
Backend features:
NoSQL databases (MongoDB, DynamoDB)
Support for migrations
Kubernetes deployment scripts
Logging and monitoring
Authentication (via multiple providers)
Payments integration (via multiple providers)
Frontend frameworks:
React (incl Redux, Hooks)
React native
Frontend features:
API calling
Views & components
Storybooks
We hope you find Imagine useful. Join our Slack and Discord communities to share your feedback and be the first to know about new releases and updates in our platform.
Before joining this project, we worked on building several compilers and implementing domain specific languages (DSLs). In all those projects, the problem to solve was more or less the same: one studies with precision the domain, then distinguishes which are the relevant components of the problem to define the syntax of the DSL, and picks a target language to give meaning/semantics to the syntax constructions.
The idea of the Imagine compiler was from the beginning ambitious: we had to capture the concepts present in any web application, define a good representation of them via some kind of DSL and then translate it to human-readable code for different frameworks. This is no easy task: although most frameworks are very similar in functionality, each one has its own idiosyncrasies, its own way of organizing components, its own representation of different concepts, etc. So, some of the challenges in comparison with our well-known recipe was that:
we don’t only use the target language to give semantics, but also as a kind of scaffolding for the developer to learn and build on top of this. The implications of this are, as we already mentioned, the code must be a good-quality, exemplary, human-readable code.
we don’t have only one target language, but as many as the universe of developers we want to cover.
Our first decision was about the programming language for implementing this code-generator. The possibility to define an Abstract Syntax Tree (AST) and easily inspect each abstract construction (i.e. characteristics of a language with native support of DSL implementations), also run different checks inside a strongly typed context were requirements for us. So, the answer to the question “Which programming language is the best for our task?” came up immediately: we definitely wanted functional programming, and given that we had enough experience with Haskell and is a widely used and supported language, we chose it. Clearly, Haskell has a lot more important features that were very useful on the implementation of the compiler, like total control about the effects on functions, all kind of monads, etc. but this post is about the design of the Imagine compiler and not Haskell publicity.
Every compiler is divided in different phases. The Imagine compiler is not an exception. From the beginning we decided to define a deep embedding: the imagine specification language consists of a Haskell AST. This specification language captures the different dynamic components of a web application like the datamodels, api endpoints, etc. From this specification, the imagine-compiler produces a complete project in the target framework (for now Django and Node.js).Having an AST gives the ability to define different concrete representations of the source language which will have the same abstract representation. Currently, we support a text representation and a UI based representation.
The first compiler phase consists of parsing, here we translate the concrete source representation into the abstract one that we call ImagineSpec. Clearly, for each different concrete representation, we need to define a different parser.
Once we have the abstract representation of the source specification, the second phase consists of doing static checks. We want to ensure that any specification produces working code in the supported frameworks, so we perform different checks over the input before generating code. Here, for instance, we do from simple checks like name clashing to some more complex ones like avoiding circular relations, among others.
The last phase is code generation. Once we have a correct abstract representation of the source specification, we produce a complete project in the specified framework.
Our first attempt was to define an abstract representation for the target languages of our compiler. We started researching the structure of Django and Node.js projects, and other backend frameworks, with the support of experts in all of them. We realized that in general, a complete web application has a lot of static code, coming from a couple of settings. Then, a considerable amount of components are built based on the information coming from the specification. We could consider the target code like static code with “holes” which will be filled with the information coming from the source specification. For instance, if we have specified a simple model with some fields, let say
model Task {
id integer [primary key]
description string [maxlength 80]
}
then a corresponding implementation in the ORM of Django and sequelize/Node.js could look like this
Django:
classTask(models.Model):
id = models.IntegerField(primary_key=True)
description = models.CharField(max_length=80)
Node.js:
consttaskModel=(sequelize)=>{
const Task = sequelize.define(
'Task',
{
id:{
type: DataTypes.INTEGER,
primaryKey:true
},
description:{
type: DataTypes.STRING,
validate:{
len:[0,80]
},
},
}
}
}
so from a closer look at these implementations, we can identify some “holes” and generalize the structures to give birth to the templates
Thus, we decided to use a template based approach using mustaches templates. In the code generation phase we write templates corresponding to code-blocks and files of the target language. These templates are rendered filling the holes with the corresponding information from the imagine spec. By serendipity now you don’t need to be a Haskell expert to implement some code generation.
Haskell allows us to implement a well modularized compiler, with separate phases in which the abstract representation of the input is the most important component. Strong types allow us to detect errors in a very easy way, and ensure correctness on each phase.
At Imagine we wanted to provide users with an all-in-one backend development experience while using the tool. From our web app, you can start a project from scratch and quickly have a backend live to play with. We wanted our users to be able to interact with their project seamlessly, and also perform tasks they usually would do locally directly from the web app, such as running tests, linting the code base, and interacting with the database.
The challenge of this task is to be able to deploy multiple entire backends quickly, allowing each user to interact with the API and directly with the database, all while running tasks on the code (linting and testing). Moreover, since with Imagine you can generate code in different frameworks (Django and Express) and with different API formats (REST and GraphQL), this environment should be available and consistent regardless of the framework-API format configuration.
We use a Node server to handle all interactions between users and their backends. It is an unusual undertaking for a server because it entails routing requests to their respective servers, and fetching and deploying said servers on-demand. Thanks to Javascript's and Node's versatility, we were able to handle all this in a very small amount of code, having our server lazily deploy a user backend and transfer control to it when a request is received.
/* Get the user project and forward the request. */
Interacting with the API and directly with the database#
Django has an excellent /admin page where you can interact directly with the ORM, and countless developers find this an excellent feature. We wanted to replicate this across all supported frameworks and API formats. After researching alternatives for admin panels, we concluded that the best experience is achieved through the default admin panel in Django and AdminBro in Node.
Similarly, an important instrument all backend developers need is an effortless way of using the API. For REST a well-known toolset is Swagger, which is the best alternative according to our research. For GraphQL the answer is straightforward: GraphiQL, which is supported by the GraphQL organization, provides everything you need in this respect.
Imagine-generated code ships with auto-generated tests and you can watch the tests running and check the coverage report right from the web app. We implemented this using a Cloud Function, which streams the test output live to the web app through Redis and uploads the coverage report afterward for the web app to see. Linting is similar, although no live streaming is necessary. As we want our users to interact smoothly with the generated code, it is imperative that the generated code be displayed as soon as possible. The core compiler is extremely fast, being compiled and optimized, but linting the files relies on external tools that take time. We therefore compromised and display code that has not been linted (though we are working on making it tidier!) but the linted code is available for download after a couple of seconds.
The Imagine compiler and its web app together comprise an orchestra of components that come together to deliver the best backend development and deployment experience possible. Implementing these building blocks required pushing available tools to the limit, and presented all kinds of challenges.
As we develop a compiler, like any other piece of software, it is crucial to implement high quality tests. But testing a compiler is not a trivial task - even if the source language is a DSL and not a complex general purpose programming language, creating test cases and checking if the compiler's output is correct can be very challenging. Let's consider the first phase of the compiler: parsing. We can understand this phase as a function from a string, representing some code in the source language, to our internal data structure that stores all relevant information. For instance, let's consider that we are only storing models and relations, and let's consider the following input for our parser:
model Person {
name string [primary key]
}
model Car {
plate string [primary key]
}
relationship Owns {
one owner from Person
many cars from Car
}
The parser will take this specification as input and produce the corresponding data structure. In case of Imagine, we choose to represent this information as an Algebraic Data Type of Haskell, which contains a list of models and a list of relationships:
data DataModelSpec =
DataModelSpec { models ::[Model]
, relations ::[Relationship]
}
So, for the example above, our parser should produce as output something like:
DataModelSpec { models =[Person, Car]
, relations =[One Person <-> Many Cars]
}
We are omitting the details of the datatypes Model and Relationship for brevity. So, to test the parser, we must produce strings that represent valid inputs, like the example above, execute the parser on it and check if the output is correct. But how could we know that the output is correct? The only tool that we have to obtain the DataModelSpec from an input is the parser, and we obviously can't use him to test itself.
The first and more straightforward way to solve this problem is to use some predefined set of test cases. This way we can manually find the expected output of each input and store them in the tests. Then we just need to check if the output of the parser matches the stored values.
Although this approach works, it has the disadvantage of being static: we will only be able to cover the corner cases that we can think about. There are all kinds of corner cases: what if there is a relation in which the two models are the same? What if there is two models with the same name? What if there is a model that doesn't exist specified in one of the relations? Our parser must behave correctly in every one of these situations. If we miss some of these corner case in the predefined tests, we can by accident accept a wrong implementation of the compiler.
Another issue with this approach is that we can’t test the performance of our compiler in larger cases, unless we put in a big amount of effort to write them by hand.
To address this issue, we need to find a way to generate random tests. This way, if we generate a large number of them, there is a good chance that each corner case will appear at least once. But, as we discussed, we can't generate directly the input strings for the parser, since we wouldn't know if the output was correct. What we decided to do instead, was to generate random DataModelSpec's, using the Hedgehog library in Haskell. Also, we created a function that, given a DataModelSpec, produces one input string that corresponds to it (essentially, the inverse function of our parser). This way, we can check our compiler by generating a large number of random DataModelSpec's, applying this new function to each one of them and run the parser over the output of the function. If the output of the parser is equal to the original DataModelSpec, then our parser is working correctly, otherwise it is not.
Of course, this approach has the disadvantage that we need to trust that we implemented the function to convert form DataModelSpec to string correctly, but this function is far more simple than our parser.
The following snippet shows one of our tests, that implements this strategy:
parseCorrectly :: Spec
parseCorrectly =
it "Should output a correct ParserOutput" $ do
(inp, expected)<-H.forAll validInput
case parse "" inp of
Left e -> failsWithParseError expected inp e
Right parsed ->H.diff parsed cmpParserOutput expected
Testing a compiler can be challenging due to the complexity of it’s output. In this article we shared a simple technique that can be very helpful to deal with this problem and that we use at Imagine in our tests, which we believe makes our compiler safer.